Spectral clustering
Given a set of data points A, the similarity matrix may be defined as a matrix 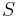 , where
, where 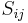 represents a measure of the similarity between points
represents a measure of the similarity between points 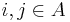 . Spectral clustering techniques make use of the spectrum of the similarity matrix of the data to perform dimensionality reduction for clustering in fewer dimensions.
. Spectral clustering techniques make use of the spectrum of the similarity matrix of the data to perform dimensionality reduction for clustering in fewer dimensions.
Contents |
Algorithms
One such technique is the normalized cuts algorithm or Shi–Malik algorithm introduced by Jianbo Shi and Jitendra Malik,[1] commonly used for image segmentation. It partitions points into two sets 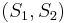 based on the eigenvector
based on the eigenvector 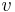 corresponding to the second-smallest eigenvalue of the Laplacian matrix
corresponding to the second-smallest eigenvalue of the Laplacian matrix
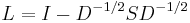
of , where 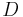 is the diagonal matrix
is the diagonal matrix
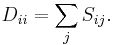
This partitioning may be done in various ways, such as by taking the median 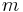 of the components in , and placing all points whose component in is greater than in
of the components in , and placing all points whose component in is greater than in 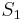 , and the rest in
, and the rest in 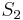 . The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in this fashion.
. The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in this fashion.
A related algorithm is the Meila–Shi algorithm[2], which takes the eigenvectors corresponding to the k largest eigenvalues of the matrix 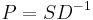 for some k, and then invokes another algorithm (e.g. k-means) to cluster points by their respective k components in these eigenvectors.
for some k, and then invokes another algorithm (e.g. k-means) to cluster points by their respective k components in these eigenvectors.
Relationship with k-means
The kernel k-means problem is an extension of the k-means problem where the input data points are mapped non-linearly into a higher-dimensional feature space via a kernel function 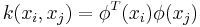 . The weighted kernel k-means problem further extends this problem by defining a weight
. The weighted kernel k-means problem further extends this problem by defining a weight 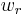 for each cluster as the reciprocal of the number of elements in the cluster,
for each cluster as the reciprocal of the number of elements in the cluster,
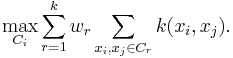
Suppose 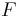 is a matrix of the normalizing coefficients for each point for each cluster
is a matrix of the normalizing coefficients for each point for each cluster 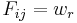 if
if 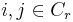 and zero otherwise. Suppose
and zero otherwise. Suppose 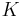 is the kernel matrix for all points. The weighted kernel k-means problem with n points and k clusters is given as,
is the kernel matrix for all points. The weighted kernel k-means problem with n points and k clusters is given as,
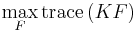
such that,
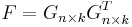
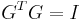
such that 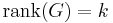 . In addition, there are identity constrains on given by,
. In addition, there are identity constrains on given by,
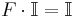
where 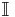 represents a vector of ones.
represents a vector of ones.
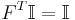
This problem can be recast as,
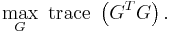
This problem is equivalent to the spectral clustering problem when the identity constraints on are relaxed. In particular, the weighted kernel k-means problem can be reformulated as a spectral clustering (graph partitioning) problem and vice-versa. The output of the algorithms are eigenvectors which do not satisfy the identity requirements for indicator variables defined by . Hence, post-processing of the eigenvectors is required for the equivalence between the problems[3].
References
- ^ Jianbo Shi and Jitendra Malik, "Normalized Cuts and Image Segmentation", IEEE Transactions on PAMI, Vol. 22, No. 8, Aug 2000.
- ^ Marina Meilă & Jianbo Shi, "Learning Segmentation by Random Walks", Processing Systems 13 (NIPS 2000), 2001, pp. 873–879.
- ^ Dhillon, I.S. and Guan, Y. and Kulis, B. (2004). "Kernel k-means: spectral clustering and normalized cuts". Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 551--556.